'1. Network > -- Fundamental (기초)' 카테고리의 다른 글
| FTP - Active & Passive 모드 차이 (0) | 2022.05.14 |
|---|---|
| [네트워크 기초 1] IPv4 Header 헤더 구조 (0) | 2021.08.09 |
| 네트워크 장비에서 항상 첫번 째 Ping 실패하는 경우 (0) | 2021.06.29 |
| FTP - Active & Passive 모드 차이 (0) | 2022.05.14 |
|---|---|
| [네트워크 기초 1] IPv4 Header 헤더 구조 (0) | 2021.08.09 |
| 네트워크 장비에서 항상 첫번 째 Ping 실패하는 경우 (0) | 2021.06.29 |
FTP는 File Transfer Protocol의 약자로 말그대로 파일을 전송하는 통신 규약입니다. FTP 서버에 파일들을 업로드, 다운로드할 수 있도록 해주는 프로토콜이며, 이는 FTP 서버와 FTP 클라이언트 간에 통신에서 이루어집니다.
FTP는 Active 모드와 Passive 모드라는 2개의 모드가 존재하며 각각의 모드에서는 2개 또는 2개 이상의 포트가 연결을 맺고 데이터를 전송하는데 사용됩니다. 사용되는 포트는 연결을 제어하는 Command 포트가 있으며 데이터를 전송하는 DATA 포트가 있습니다.
FTP는 TCP 기반으로 만들어져 있으며 기본으로 동작 모드로 Active 모드를 사용하며 20번 또는 1024번 이후의 데이터(Data) 포트는 데이터를 전송하는데 사용하게 되고, 21번 포트는 접속시에 사용되는 명령(Command )포트입니다.
Active 모드
FTP Active 모드의 동작 방식을 그림으로 보면 아래와 같습니다. 참고로 아래 사용된 명령(Command) 포트와 데이터(Data) 포트는 서버의 설정에서 임의로 수정하여 사용할 수 있습니다.

위 과정에서 액티브 모드는 “클라이언트가 서버에 접속을 하는 것이 아닌 서버가 클라이언트에 접속을 하는 것”을 확인할 수 있습니다. 만일 FTP 클라이언트에 방화벽이 설치되어 있는 등 외부에서의 접속을 허용하지 않는 상황이라면 FTP 접속이 정상적으로 이루어지지 않을 것입니다. 접소기 되더라도 데이터 목록을 받아오지 못하게 되는 경우도 있고요.
위에서 살펴본 Active 모드의 단점을 해결하기 위한 Passive 모드를 살펴봅시다. 역시나 아래 그림에서 사용된 커맨드 포트와 데이터 포트는 서버 설정에서 변경할 수 있습니다. 특히 Passive 모드에서는 데이터 포트 번호를 특별하게 지정하지 않는 경우 1024 ~ 65535번 중에서 사용 가능한 임의 포트를 사용하게 됩니다. 포트 번호를 지정할 때는 10001 ~ 10005번과 같이 범위를 지정할 수도 있습니다.

Passive 모드에서는 앞선 Active 모드에서 사용했던 20번 포트를 사용하지 않고 1024번 이후의 임의의 포트를 데이터 채널 포트로 사용하게 됩니다.
Active Mode의 경우는 클라이언트 측의 방화벽에 20번 포트가 차단되어 있다면, 데이터 채널 연결이 불가능해집니다. 연결은 되더라도 데이터 조회부터 실패되는 경우가 발생할 수 있습니다. 따라서 서버측은 20번 포트는 아웃바운드(OUTBOUND, 내 서버에서 외부서버로 보내는 요청) 허용, 클라이언트는 인바운드(INBOUND, 외부에서 내 서버로 들어오는 요청) 허용이 방화벽 설정에 필요합니다.
Passive Mode의 경우는 서버 측의 데이터 채널 포트가 막혀있는 경우 데이터 채널 연결이 불가능하게 됩니다. 그리고 앞서 소개한 것처럼 데이터 채널 포트의 범위를 지정할 수 있는데, 별도로 지정하지 않는 경우는 1024 ~ 65535번의 포트를 사용하게 됩니다. 따라서 INBOUND 모두 허용이 필요하게 되는데, 서버 측에서 데이터 채널 포트 범위를 지정하여 특정 범위의 포트만 허용해주면 모든 포트 허용의 문제를 어느 정도 해결할 수 있습니다.
| 와일드카드 마스크 예제 (Wildcard Mask) (0) | 2022.05.15 |
|---|---|
| [네트워크 기초 1] IPv4 Header 헤더 구조 (0) | 2021.08.09 |
| 네트워크 장비에서 항상 첫번 째 Ping 실패하는 경우 (0) | 2021.06.29 |
- 모든 filter들은 incoming and outgoing updates 에게 적용 된다.
- outbound 정책 변경 시, Neighbor들에게 BGP Update 메시지를 재전송해야 된다. (내가 전송)
- inbound 정책 변경 시, Neighbor들이 BGP Update 메시지를 보낼 수 있게 해야 된다. (Neighbor들이 나에게 전송)
- 전동적인 매커니즘은 BGP Session을 초기화 시키는 것.
- 명령어 : clear ip bgp { * | neighbor ip address | peer-group}
해당 명령어로 bgp 전체의 session을 초기화 할지, 아니면 특정 neighbor나 peer-group에게만 적용 할 수 있다. 그리고 명령어 실행 후 BGP Session은 즉시 끊어지며 BGP Session 재 수립시 까지 짧으면 30초에서 길면 60초 까지 소요 된다. (BGP Table이 클 경우 Best Path를 찾는데 시간이 더 걸릴 수 있음)
session 재 수립 시 전체 라우팅 업데이트가 교환되고 결과적으로 새로운 정책이 적용이 되는 것이다. 하지만 전체 Internet routing table을 교환하는데 굉장히 많은 시간이 소요 되고 clear ip bgp는 라우팅 정책 교환의 방법으로써는 권장하지 않는다.
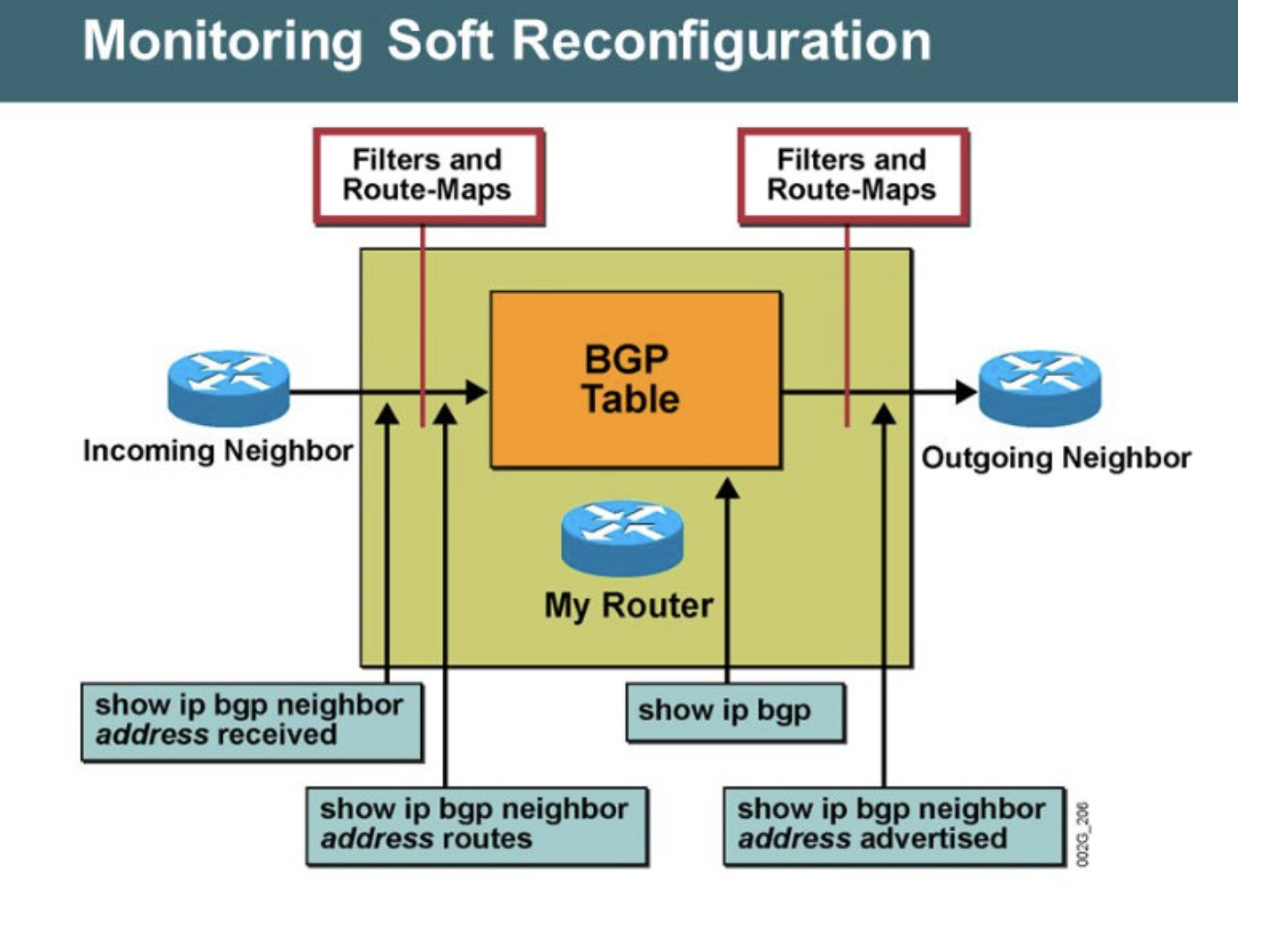
BGP - Soft Reconfiguration
- Soft Reconfiguration은 Cisco IOS 11.2 이후 부터 공표되었고 BGP정책 교환 시 BGP Session에 지장을 주지 않는 방법이다.
- outbound soft reconfiguration은 완전한 BGP Table을 재전송
(항상 enable되어 있으며, 별도의 설정은 필요치 않습니다.)
- inbound soft reconfiguration은 Neighbor로 부터 수신한 BGP Table을 라우터 메모리에 저장해 두었다가 적용한다.
(이 방식의 단점은 많은 메모리를 소모하는 것이 단점이다.)

BGP Soft Reconfiguration을 사용 하였을 때 라우터에서 사용하는 메모리 정보이다. 각 ISP로 부터 100,000개의 라우팅 정보를 받고 Best-Path를 선출 해서 RIB(100,000)로 내리고 RIB를 기반으로 해서 FIB Table(100,000)을 만들게 된다. 즉, BGP Table + RIB + FIB 테이블의 총 합 500,000개의 테이블이 생성되게 되며 이것을 하나의 라우터에서 관리되게 되는 것이다.
Soft Reconfiguration을 사용할 경우 show ip bgp neighbor 명령어로 경로 출력 시 보여지는 부분이 다르다.

현재 BGP상에 아무런 정책도 설정하지 않은 상태에서 R2에서 BGP Table을 확인 해 보면 전체 BGP 경로를 정상적으로 수신하고 있는 것을 확인 할 수 있다.
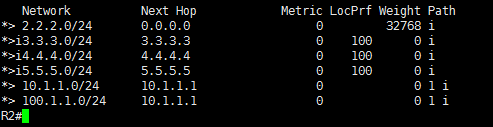
Inbound정책의 수정이 없으니 당연히 모든 경로를 정상적으로 수신하고 있고, 이제 R2에서 정책을 수정 한 뒤 Neighbor인 R1에게 soft reconfiguration을 적용시켜 보도록 하자.
변경하고자 하는 정책은 R1에서 광고하는 100.1.1.0/24 네트워크 정보의 weight 값을 100으로 올리는 inbound설정을 변경 하였다.

실제 장비였다면 clear ip bgp 10.1.1.1 soft in 명령어를 줘야 적용이 될 것인데, GNS라서 그런지 clear ~ 명령어를 주지 않아도 알아서 정보를 요청하는 debugging 메시지를 볼 수 있다.

R2에서 route-map이 적용 된 BGP Table정보를 보면 10.1.1.0/24 Network대역은 필터링이 되었고 100.1.1.0/24의 Weight 속성은 100으로 증가 된 것을 확인 할 수 있다. 그렇다면 soft reconfiguration의 동작을 show ip bgp neighbor 명령어로 알아보자.

R2에서 received-route 명령어 수행 시 메모리에 있는 정보가 출력이 된다. 해당 정보는 아직 route-map에 의해서 수정이 되지 않은 정보가 보여지는 것이다.

R2에서 route-map에 의해서 필터링(10.1.1.0/24) 되고 속성(weight 값이 100으로 변경 됨) 이 변경 된 정보가 보여진다.
BGP 정책 변경 적용 시 clear ip bgp [ip address] soft in
해당 명령어로 변경 된 정책을 적용 시키면 되고, BGP Session이 끊어 지지 않고 변경 된 정책이 적용 된다.
outbound정책 적용은 clear ip bgp [ip address] soft out 이다.
(inbound처럼 별도의 설정은 필요치 않다.)
* soft reconfiguration이 설정되어 있지 않다면 received-route명령어 수행 시 오류 메시지가 발생한다.
| ② BGP 경로에 포함되는 속성들 (Path Attributes) (0) | 2022.08.04 |
|---|---|
| ① BGP 소개 및 특징 (0) | 2022.08.04 |
| [BGP] 기본설정 이슈 3가지 Issue - (1) synchronization 문제 및 해결방법 3가지 (0) | 2022.04.26 |
| [ BGP ] 기본설정 3가지 Issue - (2) Next-Hop 문제 및 해결방법 2가지 (0) | 2022.03.25 |
| [BGP] 기본설정 3가지 Issue - (3) Split Horizon 문제 및 해결방법 3가지 (0) | 2022.03.24 |
BGP 동기화는 BGP에 의해 학습한 네트워크를 IGP에서도 학습되어져 BGP 와 IGP 가 서로 동기화 되어야 한다는 것
다시한번 정리해보면 다음과 같다.
"IBGP 로 광고받은 네트워크는 IGP가 확인해주어야 한다."
(BGP 동기화는 ibgp 경로에 대해서만 동기화 규칙이 적용된다.)
BGP 동기화 문제는 AS내에 모든 라우터가 BGP를 수행할 경우 활용할 필요가 없다.
그러나 문제되는 경우를 살펴보면 AS내에 모든 라우터들이 BGP를 수행하지 않을 경우 블랙홀 현상이 발생 할 수도 있다.
이러한 문제에 따라 동기화 법칙을 만족 시켜 주어야 하는데 만족 시키기 위한 방법으로 3가지가 있다.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
1. no synchronization
위에 설명과 같이 AS내의 모든 라우터가 BGP를 사용한다면 동기화 법칙을 사용하지 않아도 문제가 되지 않는다.
이에 no synchronization 명령어를 통해 BGP 동기화 법칙을 적용시키지 않을 수 있다.
최근 발표된 IOS들은 기본적으로 "no synchronization" 이다.
그렇다면 synchronization 을 켰을 때 문제가 되는 상황을 확인해보자.

# 이와 같이 AS 내에 모든 라우터가 BGP 를 사용할 시에 no synchronization 로 간단히 해결 할 수 있다.
2. BGP를 IGP에 재분배
IGP 에서 BGP정보를 재분해 해줌으로 IGP가 BGP정보를 알게 됨으로 IBGP 와 IGP 간 동기화를 이룰 수 있다.
Lab을 통해 블랙홀 현상이 일어날 시 재분배로 문제를 해결해 보자.

# 블랙홀 현상을 만들기 위해 AS 24 에서 BGP 를 R2 와 R4 만 설정하고 R3는 설정하지 않는다.
참고로 라우터 밑에 IP 는 루프백 주소이자 Router ID 로 설정한다.
위와 같이 Topology를 설정했다면 위에 설명과 같이 R3가 블랙홀 상태가 될 것이다. 이에 따른 해결로 재분배를 통해 해결해 보자.
config 방법은 생략하고 모든 config가 이루어 졌을 때 BGP Table을 보자.


# 모두 문제 없이 Besth Path를 잡는다. 그러나 실제 Ping을 해 볼 때 제대로 가지 않는 현상을 보인다.

# 왜 이런 현상이 일어날까? 이유는 R3 라우터에 있다.

예를 들어 , R1 에서 1.1.1.0/24 네트워크 정보를 전달 할 때 R2까지 잘 전달이 된다. 그런데 R2의 네이버인 R4는 직접적으로 연결된게 아니라
R3를 통해 연결되기 때문에 , R3는 BGP가 설정되어 있지 않으므로 R4에게 네트워크 정보만 라우팅 시킨다.
이로 인해 R4와 R5는 1.1.1.0/24 네트워크에 대해 BGP 테이블과 라우팅 테이블에 저장 시킨다.
그런데 이 때 R5에서 1.1.1.0/24에 패킷을 보낸다면 패킷의 흐름을 보면 목적지를 1.1.1.0/24로 하여 송신을 하는데 ,
R4까지 거처 R3에 도달했을때 문제가 발견된다. R3입장에서는 BGP로 받은정보를 당연히 라우팅 테이블에 저장시키지 않으므로
R3에서는 1.1.1.0/24 네트워크가 존재하지 않는다. 그러므로 Ping Test 시 도달하지 못한다.
한마디로 블랙홀 상태!!

3. Confederation
Confederation은 하나의 AS에서 서브 AS를 생성하는 것이다.
이렇게 되면 하나의 AS에 라우터들이 서로 다른 AS갖게 되어 iBGP 가 아닌 ebgp 로 정보를 주고 받게 된다.

# 이렇게 되면 R2 ,R3, R4 간이 iBGP로 정보를 보내는 것이 아니라, eBGP 로 보냄으로 Synchronization 이 해결된다.
맨 위에서 설명한대로 , 기본적으로 동기화는 iBGP 내에서만 적용하므로 eBGP로 정보를 보내니 동기화 문제는 해결된다.
Confederation은 설정법은 다음과 같다.

# 이렇게 AS 내 라우터에 설정함으로 IBGP 가 아닌 eBGP 정보로 주고 받게 한다.
여기서 ebgp-multihop은 Next-hop-address 가 Connect 가 아닌 네트워크를 함으로 설정해 주는데 뒤에 홉카운트는
시작 라우터와 도착지 라우터까지 포함한 Hop Count 로 한다. 초과해도 좋으나 보안상 문제로 알맞게 맞추어 주는것이 좋다.
| ② BGP 경로에 포함되는 속성들 (Path Attributes) (0) | 2022.08.04 |
|---|---|
| ① BGP 소개 및 특징 (0) | 2022.08.04 |
| BGP - 정책 변경 적용 (Soft Reconfiguration) (0) | 2022.04.29 |
| [ BGP ] 기본설정 3가지 Issue - (2) Next-Hop 문제 및 해결방법 2가지 (0) | 2022.03.25 |
| [BGP] 기본설정 3가지 Issue - (3) Split Horizon 문제 및 해결방법 3가지 (0) | 2022.03.24 |
시스코 라우터에서는 default로 enable 되어 있고,
소스 ip datagram에 header option의 조작을 허용하는 명령어라고 나와있고
no를 앞에 붙이면 반대의 경우라고 나와 있더구군요 그러면서 관련된 명령으로 ping을 예를 들고 있구요.
그래서 enable과 disable을 반복하면 소스 ping을 test해 보았는데 별다른 차이점은 확인을 못하였습니다.
ping명령어는 아시져..^===^ 근데 -r 옵션은 써보셨나여..?
ping -r (=이 옵션을 쓰시게 되면..자신이 원하는 게이트웨이를 거쳐서 routing이
될 수 있읍니다.)
즉, ping -r gateway1 gateway2 ....이런식으로 지정이 가능합니다.
(traceroute도 위와 같은 옵션이 있읍니다. 이부분도 참고 하시고여..)
저런 식으로 우리가 ping 명령어를 쓸수 있게 된것은 ip header 안에 source route option field 가 있기 때문입니다. 즉 위와 같이 ping -r 하시면
ip hearder 안의 옵션 필드에는 gateway1 gateway2 하고 기록이 되어서 ping패킷이 나가게 되어있읍니다.
source route option field가 있기 때문에 라우터는 ip header를 까보고 첫번째 gateway는 gateway1( xx.xx.xx.xx)라는 것을 알게 되고 gateway1에 도착해서는 거기서 다시 gateway2로 가라는 사실을 알수가 있읍니다..(즉 라우팅이 목적지에 의해서 결정되는 것이 아니라 소스가 지정해준 라우팅을 타고 나가서 source route option field라고 지칭하는 것 같습니다.)
그런데 라우터에서 no ip source route을 하시게 되면 이와같은 라우터의 특성을 무시하라는 명령어가 됩니다. 즉 자신이 ping -r 로서 gateway를 지정해 줘봤자..라우터에서는 ip header의 source route option field 값을 무시하므로 일반적인 라우팅을 타고 나가게 됩니다.. 반대의 경우라면 라우팅 테이블을 참조하기 전에 ip header의 source route option field 부터 적용이 되고요.
소스ping ( extended ping 이야기 하시는 거져..라우터에서 쓰는) 을 라우터에서 해봤자 ip source route과는 전혀 관계가 없겠져..no ip source route명령어를 확인해 보시고 싶으시면 라우터가 아닌 PC에서 ping -r 명령어나 traceroute명령어로 확인하시는 것이 빠릅니다.
그런데 이 ip source route명령어는 보안과 아주 밀접한 관련이 있다고 말 할 수 있읍니다. 함부로 enable 시키면 보안에 구멍이 날 수도 있겠져..
그래서 cisco에서는 12.0version(check해봐야 알겠는데여 ^^) 이상은
모두 no ip source route가 default 명령어 로 입력되어 있는 것으로 알고 있읍니다.
답변이 짧고 주저리 주저리 써서 이해가실런지 몰겠읍니다. 도움이 되었으면 좋겠읍니다.^^
IP header중에 source route option field에 대해서 자세히 아시고 싶으시면 TCP/IP illustrated vol1을 참조하시면 아주 설명이 잘 나와있읍니다.
| Cisco IOS Platform에서 지원하는 3가지 IP L3 Switching 메커니즘 (0) | 2022.04.18 |
|---|---|
| Cisco 보안 취약점 설정 가이드 (0) | 2022.04.18 |
| Cisco - DAI란? (Dynamic ARP Inspection) (0) | 2021.07.25 |
>> Process Switching
(( 스위치는 맨 처음 이 방식으로 처리 ))
라우터가 각각의 패킷을 전송할 때마다 라우팅 테이블을 확인하고 넥스트 홉을 결정하여 패킷을 전송하는 방식을 Process Switching 이라고 합니다.
이 방식은 라우터의 CPU에 많은 부하가 걸리고 스위칭 속도도 느립니다. 또 패킷별로 로드 밸런싱(Load Balancing)이 이루어집니다. 즉 각각의 패킷별로 스위칭을 하기 때문에 목적지로 가는 경로가 2개 있을 경우에는 패킷별로 한번씩 한번씩 다른 경로로 전송합니다
Process Switching 방식으로 동작시키려면 해당 인터페이스에
"Router(config-if)#no ip route-cache" 명령을 입력하면 됩니다
——> no ip route-cache 는
프로세스 스위칭으로 바꾸는 것으로
옛날방식으로 바꾸는 것.
그래서 옛날 스위치는 기본으로 있음
지금은 기본으로 “ip-route-cache” 되있음
>> Fast Switching
라우터가 특정 목적지로 전송되는 패킷에 대하여 처음 한번은 Process Switching을 하고 두 번째부터는 처음 Process Switching 때 만든 캐쉬 정보를 이용하여 패킷을 전송하는 방식을 Fast Switching 이라고 합니다.
Default Switching 방식입니다. 이 방식은 목적지별로 로드 밸런싱(Load Balancing)이 이루어집니다
Fast Switching 방식으로 동작시키려면 해당 인터페이스에
"Router(config-if)#ip route-cache" 명령을 입력하면 됩니다
>> CEF(Cisco Express Forwarding) Switching
(( IOS 12.4 에서는 CEF 가 default ))
Fast Switching 방식을 다음과 같이 개선한 방식입니다. Fast Switching 방식은 처음 한번은 Process Switching을 해야 캐쉬가 생성되지만 CEF Switching 방식은 처음부터 라우팅 테이블을 캐쉬로 복사해 놓습니다. 캐쉬를 검색하는 속도도 더 빠릅니다. Fast Switching 방식은 목적지 주소와 그 목적지로 가는 경로를 기록하지만 CEF Switching 방식은 목적지 주소와 함께 출발지 주소, 목적지로 가는 경로가 기록됩니다. 이 방식은 출발지 -> 목적지별로 로드 밸런싱(Load Balancing)이 이루어집니다. 단, interface mode로 들어가서 ip load-sharing per-packet 명령을 넣어주면 패킷별로 로드 밸런싱 가능합니다. CEF Switching 방식으로 동작시키려면 전체 설정모드에서
"Router(config)#ip cef" 명령을 입력하면 됩니다.
| ip source-route 명령어 (0) | 2022.04.18 |
|---|---|
| Cisco 보안 취약점 설정 가이드 (0) | 2022.04.18 |
| Cisco - DAI란? (Dynamic ARP Inspection) (0) | 2021.07.25 |
1. no ip unreachables -> Cisco 장비의 경우 ICMP unreachable 메시지는 목적지 호스트가 네트워크 상에 존재하지 않을 경우, 네트워크 장비가 소스 호스트에 전송하는 메시로서 이를 악용하는 불법 사용자는 이 기능을 이용하여 네트워크 상에 실제로 동작하는 장비를 리스팅하고 스캔 범위를 결정하게 된다.
출처: https://wantyou7.tistory.com/16 [베롱쓰의 Level Up]
패킷이 Null interface로 보내어져 패킷이 filtering될 때마다 패킷의 source ip로 icmp unreachalbe이라는 에러메시지를 보내게 되는데, 필터링 하는 패킷이 많을 경우에는 Router에 과부하를 유발할 수 있기 때문에 icmp에러메시지를 응답하지 않도록 하는 것이 좋다
2. no ip redirects
-> ICMP redirects는 라우터가 로컬 서브넷의 호스트에게 목적지까지의 경로로서 자신이 아닌 다른 라우터를 사용하게끔 하는 기능으로, 호스트가 보유한 라우팅 테이블이 최적의 정보를 갖게 하는 것을 목적으로 한다. 악의적인 공격자들은 이런 기능을 이용하여 ICMP redirect를 전송하여 네트워크를 지나는 패킷의 방향을 바꿀 수 있다.
출처: https://wantyou7.tistory.com/16 [베롱쓰의 Level Up]
3. no ip proxy-arp
-> Cisco 라우터는 디폴트 라우터나 Gateway를 가지고 있지 않는 네트워크의 호스트들에게 ARP 서비스를 제공하는 역할을 한다. 이 경우에 호스트가 목적지 IP 주소에 대한 MAC 주소를 요청하면 Proxy ARP를 요청하여 라우터가 이에 응답하는 것을 이용하여 라우터와 네트워크에 관련된 정보를 획득할 수 있다.
출처: https://wantyou7.tistory.com/16 [베롱쓰의 Level Up]
| ip source-route 명령어 (0) | 2022.04.18 |
|---|---|
| Cisco IOS Platform에서 지원하는 3가지 IP L3 Switching 메커니즘 (0) | 2022.04.18 |
| Cisco - DAI란? (Dynamic ARP Inspection) (0) | 2021.07.25 |
# ex) 4대의 장비가 있으면 4대 모두 OSPF full
neighbor 가 되야하는 조건
1. 물리적으로 직접 연결된 네트워크 여야 함
2. 같은 Area 여야함
| ⑤ OSPF DR / BDR 란? (0) | 2022.08.04 |
|---|---|
| ④ OSPF Network Type 이란? (0) | 2022.08.04 |
| ③ OSPF Neighbor 종류 와 상태 (0) | 2022.08.04 |
| ② OSPF Packet Type (Hello, DBD, LS R/U/A) (0) | 2022.08.04 |
| ① OSPF Routing Protocol - 정의 및 특징 (0) | 2022.08.04 |
* Next hop Issue *
1) [ Next Hop Address ]
목적지 네트워크로 가기 위한 다음 라우터를 Next hop 이라 하고 이 IP 주소를 Next hop address 라고 한다.
일반적으로 알고 있던 IGP에서 Next hop address 는 Connect된 인접 라우터 인터페이스 주소로 하나
BGP에서 Connect 된 주소나 Connect 되지 않은 주소 모두 사용이 가능하다.
또 BGP Next hop 특징은 다른 AS로 넘어갈 때는 경계 라우터를 Next hop으로 하고
같은 AS 내부 일 경우 꼭 인접라우터를 Next hop 으로 하여 거쳐갈 필요가 없다.

# R1 에서 R4 의 1.1.4.0 네트워크로 가기 위해 Next hop address 는 먼저 AS가 바뀌는 시점에 경계라우터 R2를 Next hop 으로 하고
다음으로 같은 AS에서 직통으로 R4를 Next hop으로 한다.
만약 모두가 같은 AS라면 한번에 R4로 Next hop으로 잡을 것이다.
BGP에서 Next hop은 이정도로 설명하고 Next hop 문제에 대해 알아보자.

[이슈]
: R3 , R4 에서 R1----R2 사이 연결된 네트워크 (1.1.1.0/24) 를 모른다면 R1 네트워크로 도달 할 수 가 없다.
일단 R1으로 가기위해 경계라우터인 R2로 도달해야되는데 라우팅 테이블에 업으니까 말이다.
(1.1.1.0/24 네트웍이 R3, R4 라우팅테이블에 업으니 R2로 갈수도 업는것)
[ Next-hop 문제 2가지 방법으로 해결 ]
위와 같게 Lab을 통해 알아보자.

* AS 234에 IGP를 OSPF로 사용하는데 R1과 R2 연결 네트워크는 제외한다.
R3에서 BGP Table 과 Routing Table 을 보면 다음과 같다.

이를 해결하기 위해 R3와 R4 라우팅 테이블에 1.1.12.1 네트워크 정보를 추가 시킨다.
R2에서 OSPF를 설정할 때 1.1.12.1 도 포함 시킨다. 그러고 난 후 R3 테이블 보자.

이로써 IGP에서 DMZ를 추가함으로 Next-hop 문제를 해결하였다.
2) Next-hop-self 명령어
이번에는 next-hop-self 명령어를 통해 Next-hop-self 문제를 해결해 보겠다.
좀 전에 IGP에서 DMZ 구간인 1.1.12.0 네트워크를 삭제하고 R3를 보면 아까 위에 테이블과 마찬가지로 나타날 것이다.
이 때 R2에서 Next-hop 을 자신으로 한다는 명령어인 Next-hop-self 를 사용한 후 R3를 보면 다음과 같다.


* 1.1.1.0/24 에 대한 Next-hop 이 1.1.12.1 에서 R2 Router-id 인 1.1.2.2 로 변경됨으로 R3와 R4에서 도달이 가능해 졌다.
>> 이상으로 Next-hop 문제 해결 방법인 'DMZ 구간을 IGP에서 포함 시키기' 와
'Next-hop-self 명령어를 통한 해결' 를 알아보았다.
1.
https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=kwi3094&logNo=120044167684
BGP (3) _ 기본 설정 3가지 Issue - ② Next Hop , ③ Split Horizon
2. Next Hop Issue 1) Next Hop Address 목적지 네트워크를 가기 위한 다음 라우터를 Next Hop이라...
blog.naver.com
2.
https://blog.naver.com/happy_jhyo/221287317330
BGP Next-Hop-Self 내마음데로 이해하기.
- E-BGP에서 전달 받은 BPG정보는 I-BGP 내부로 흘러 들어 갈 수 있는가? 답변은 No 이다. - ...
blog.naver.com
3.
https://peemangit.tistory.com/m/136
[Router] BGP(Border Gateway Protocol) 개념 및 설정 (2 / 2)
BGP 개념 및 eBGP 설정을 보시려면 아래 링크 클릭! BGP 개념 및 설정(1/2) [Router] BGP(Border Gateway Protocol) 개념 및 설정 (1 / 2) BGP(Border Gateway Protocol) 개념 - TCP 포트 179번을 사용하고 유니캐..
peemangit.tistory.com
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
| ② BGP 경로에 포함되는 속성들 (Path Attributes) (0) | 2022.08.04 |
|---|---|
| ① BGP 소개 및 특징 (0) | 2022.08.04 |
| BGP - 정책 변경 적용 (Soft Reconfiguration) (0) | 2022.04.29 |
| [BGP] 기본설정 이슈 3가지 Issue - (1) synchronization 문제 및 해결방법 3가지 (0) | 2022.04.26 |
| [BGP] 기본설정 3가지 Issue - (3) Split Horizon 문제 및 해결방법 3가지 (0) | 2022.03.24 |
1. [ BGP Split Horizon 이슈 ]
보통 알고 있던 IGP 에서 Split-horizon과 BGP에서의 Split-horizon은 의미가 약간 다르다.
BGP에서 Split-horizon은 'iBGP로 광고받은 네트워크는 iBGP로 전달하지 못한다' 이다.
그림을 통해 알아보자.

* 1.1.1.0 네트워크를 광고할 때 R3 입장에선 R2에게 iBGP로 광고를 받으나 R4에게 iBGP로 광고해야 하므로 Split horizon 규칙이 깨진다.


이런 Split horizon 문제가 발생하기 때문에 이를 해결해 주어야 하는데 3가지 방법으로 해결해 본다.
(1) Full Mesh 설정
(2) Route-Refelector 설정
(3) Confederation 설정
2. BGP Split horizon 해결 방법
1. Full mesh
full mesh 로 설정함이란 AS 내 모든 라우터 끼리 네이버를 맺는 것을 말한다.
위 Lab 에서 보면 R2가 R3 뿐 아니라 R4까지 네이버를 맺고 R4에서 R2까지 네이버를 맺는다.
그러면 어떻게 동작할 지 보자.

* R2에서 R4로 직통으로 iBGP로 전달해준다. 그러므로 Split horizon 문제는 해결된다.
config 후 라우팅 테이블을 보면


* 모든 경로 가는 BGP Table이 완성 되었다.
2. Route-Reflector
Route-reflector 는 split horizon 을 적용하지 않겠다고 선언하는 것이다.
즉 Router-reflector Client는 Split horizon 규칙을 적용하지 않는다.

* 이와 같이 R3를 RR로 하고 네이버 인 R2와 R3 를 RRC(Route-Reflector-Client)로 하면
Split-horizon 규칙이 적용하지 않아 광고받은 iBGP 정보를 iBGP로 광고 할 수 있다.
명령어는 neighbor [Next hop] route-reflector-client 로 R3에서 R2와 R4를 RRC로 잡아주면 된다.
그러면 모든 BGP 정보가 전달되어 완벽한 BGP Table이 완성 된다.
>> RR에 대한 설명은 간단히 하고 넘어가고 추후에 BGP 속성을 알아볼때 자세히 하도록 한다.
3. Confederation
Confederation은 앞 포스트인 동기화에서 설명하였듯이 주 AS를 서브 AS로 나누어 준다.
그러면 AS 내에서 iBGP로 정보를 보내는것이 아닌 eBGP로 보내므로 Split horizon 문제가 해결된다.

* Confederation 을 하여 BGP Split horizon 문제를 해결 하였다. 이로써 완벽한 BGP Table이 완성 된다.
>> 위 3가지 방법을 통해 BGP Split-horizon 문제를 해결 할 수 있다. 상황에 따라 다르지만 보통 RR을 사용하여 해결하는 경향이다.
https://totori.tistory.com/482
BGP 스플릿 호라이즌
※ BGP 스플릿 호라이즌 - iBGP로 광고받은 네트워크는 iBGP로 광고하지 못한다. 즉, iBGP 네이버에게서 광고받은 네트워크에 관한 라우팅 정보는 다른 iBGP 네이버에게 전달하지 못한다. 다음 그림
totori.tistory.com
[ 해결방법 1 ]
1. Full-Mesh 설정
https://totori.tistory.com/483?category=660226
완전 메시 설정 Full mesh
완전 메시 설정 (full mesh) - iBGP 라우터에게 모든 iBGP 라우터들과 네이버를 맺도록 수동으로 설정한다. 즉, R2는 R3 하고만 네이버 관계를 맺고 있으나 완전 메시 설정으로 R4 하고도 네이버를 맺는
totori.tistory.com
[ 해결방법 2 ]
2. 루트 리플렉터 설정
https://totori.tistory.com/484?category=660226
루트 리플렉터 route reflector
▶ 루트 리플렉터 (route reflector) - iBGP 스플릿 호라이즌 규칙이 적용되지 않는 라우터를 말한다. 즉, iBGP 네이버중에서 루트 리플렉터 클라이언트 대해서는 iBGP 스플릿 호라이즌 룰을 적용하지
totori.tistory.com
[ 해결방법 3 ]
3. Confederation (컨페더레이션) 설정
https://totori.tistory.com/485?category=660226
컨페더레이션을 이용한 BGP 스플릿 호라이즌 해결
▶ 컨페더레이션을 이용한 BGP 스플릿 호라이즌 해결 컨페더레이션을 사용하면 iBGP 네이버가 eBGP 네이버로 변경되기 때문에 iBGP로 받은 네트워크는 iBGP로 보내지 못한다.스플릿 호라이즌 룰 자
totori.tistory.com
4.
https://peemangit.tistory.com/m/136
[Router] BGP(Border Gateway Protocol) 개념 및 설정 (2 / 2)
BGP 개념 및 eBGP 설정을 보시려면 아래 링크 클릭! BGP 개념 및 설정(1/2) [Router] BGP(Border Gateway Protocol) 개념 및 설정 (1 / 2) BGP(Border Gateway Protocol) 개념 - TCP 포트 179번을 사용하고 유니캐..
peemangit.tistory.com
| ② BGP 경로에 포함되는 속성들 (Path Attributes) (0) | 2022.08.04 |
|---|---|
| ① BGP 소개 및 특징 (0) | 2022.08.04 |
| BGP - 정책 변경 적용 (Soft Reconfiguration) (0) | 2022.04.29 |
| [BGP] 기본설정 이슈 3가지 Issue - (1) synchronization 문제 및 해결방법 3가지 (0) | 2022.04.26 |
| [ BGP ] 기본설정 3가지 Issue - (2) Next-Hop 문제 및 해결방법 2가지 (0) | 2022.03.25 |

\
Version 필드 (4bit)
: TCP/IP 제품은 IP v4를 사용한다.
Header Length 필드(4bit)
: IP 헤드의 길이를 32비트 단위로 나타낸다. 대부분의 IP 헤더의 길이는 20바이트 입니다. 필드 값은 거의 항상5다
(5 * 32 = 160bit or 20Byte)
Type-of-Service Flags
; 서비스의 우선 순위를 제공한다.


Total Packet Length 필드 (16bit)
; 전체 IP 패킷의 길이를 바이트 단위로 나타낸다.
Fragment identifier 필드 (16bit)
; 분열이 발생한 경우, 조각을 다시 결합하기 원래의 데이터를 식별하기 위해서 사용한다.
Fragmentation Flags 필드 (3bit)
; 처음 1bit는은 항상 0으로 설정, 나머지 2비트의 용도는 다음과 같다.
- May Fragment : IP 라우터에 의해 분열되는 여부를 나타낸다. 플래그 0 - 분열 가능 1 - 분열 방지
- More Fragments : 원래 데이터의 분열된 조각이 더 있는지 여부 판단.
플래그 0 - 마지막 조각, 기본값 1- 조각이 더 있음
Fragmentation Offset 필드 (13bit)
; 8바이트 오프셋으로 조각에 저장된 원래 데이터의 바이트 범위를 나타낸다.

Time-to-live 필드(8bit)
; 데이터을 전달할 수 없는 것으로 판단되어 소멸되기 이전에 데이터가 이동할 수 있는 단계의 수를 나타낸다.
Time-to-Live 필드는 1에서 255사이의 값을 지정하며 라우터들은 패킷을 전달 할 때마다 이 값을 하나씩 감소시킨다.
Protocol Identifier 필드(8bit)
;상위 계층 프로토콜
1 - ICMP, 2 - IGMP, 6 - TCP, 17 - UDP
Header Checksum 필드(16bit)
; IP 헤더의 체크섬을 저장, 라우터를 지나갈때 마다 재 계산을 하기 때문에 속도가 떨어진다.
Source IP Address 필드(32bit)
; 출발지 IP 주소
Destiantion IP Address 필드(32bit)
; 목적지 IP 주소
Options(선택적) 필드(가변적)
; Type-of-Service 플래그 처럼 특별한 처리 옵션을 추가로 정의 할 수 있다.
감사합니다.
| 와일드카드 마스크 예제 (Wildcard Mask) (0) | 2022.05.15 |
|---|---|
| FTP - Active & Passive 모드 차이 (0) | 2022.05.14 |
| 네트워크 장비에서 항상 첫번 째 Ping 실패하는 경우 (0) | 2021.06.29 |
DAI (Dynamic ARP Inspection)
DAI는 스위치 보안 기능으로 네트워크 내에 ARP 패킷의 정당성을 확인하여 통신하게 해주는 설정입니다.
MITM (Man in the Middle) 공격과 같이 MAC, IP의 ARP 패킷을 가로채 훔쳐보거나, 위조하여 공격하는
ARP Poisoning 등을 막기 위하여 사용하는 기능입니다.
DAI는 Untrust로 설정된 인터페이스에서 통신되는 패킷을 가로채 확인하여 옳지 않은 MAC-IP 패킷을 로그로 남기고 버린다. Trust된 인터페이스로 패킷이 들어오면 통과시킨다.
정확한 MAC-IP의 정당성을 확인하기 위해 DHCP Snooping에 의해 미리 생성된 데이터베이스를 활용한다.
ACL을 설정하면 DHCP Snooping 보다 우선시 한다. ACL에 거부된 패킷은 DHCP Snooping 데이터베이스를 보지도 않고 거부한다.

유저 인터페이스들은 아래와 같이 설정하였습니다
SW1(config)#ip arp inspection vlan 10
SW1(config)#interface range ethernet 0/1 - 3
SW1(config-if-range)#ip arp inspection limit rate 50
DHCP Server와 연결된 인터페이스는 아래와 같이 설정하였습니다.
SW1(config)#interface ethernet 0/0
SW1(config-if)#ip arp inspection trust
ip arp inspection vlan [Vlan ID] - DAI를 적용할 Vlan을 입력해주세요.
ip arp inspection limit rate [num] - 신뢰하지 않는 인터페이스에 초당 ARP 패킷 수를 조절한다. (넘으면 차단)
ip arp inspection trust - 스위치가 연결되어있거나 신뢰가능한 인터페이스에 설정해 주세요.
테스트로 Untrust 인터페이스에서 ARP 패킷을 전송해 보겠습니다.
*Jun 30 11:51:48.183: %SW_DAI-4-DHCP_SNOOPING_DENY: 1 Invalid ARPs (Req) on Et0/2, vlan 10.([0050.7966.6804/192.168.10.200/ffff.ffff.ffff/192.168.10.200/13:51:47 EET Tue Jun 30 2020])
*Jun 30 11:51:49.186: %SW_DAI-4-DHCP_SNOOPING_DENY: 1 Invalid ARPs (Req) on Et0/2, vlan 10.([0050.7966.6804/192.168.10.200/ffff.ffff.ffff/192.168.10.200/13:51:48 EET Tue Jun 30 2020])
*Jun 30 11:51:50.187: %SW_DAI-4-DHCP_SNOOPING_DENY: 1 Invalid ARPs (Req) on Et0/2, vlan 10.([0050.7966.6804/192.168.10.200/ffff.ffff.ffff/192.168.10.200/13:51:49 EET Tue Jun 30 2020])이와같이 패킷이 DENY 됩니다.
DAI 설정된 포트를 확인할 수 있습니다.
SW1#show ip arp inspection interfaces
Interface Trust State Rate (pps) Burst Interval
--------------- ----------- ---------- --------------
Et0/0 Trusted 50 1
Et0/1 Untrusted 1 1
Et0/2 Untrusted 50 1
Et0/3 Untrusted 50 1
DAI 설정된 정보를 볼 수 있습니다.
SW1#show ip arp inspection statistics
Vlan Forwarded Dropped DHCP Drops ACL Drops
---- --------- ------- ---------- ---------
10 5 21 21 0
Vlan DHCP Permits ACL Permits Probe Permits Source MAC Failures
---- ------------ ----------- ------------- -------------------
10 0 0 0 0
Vlan Dest MAC Failures IP Validation Failures Invalid Protocol Data
---- ----------------- ---------------------- ---------------------
10 0 0 0
감사합니다.
| ip source-route 명령어 (0) | 2022.04.18 |
|---|---|
| Cisco IOS Platform에서 지원하는 3가지 IP L3 Switching 메커니즘 (0) | 2022.04.18 |
| Cisco 보안 취약점 설정 가이드 (0) | 2022.04.18 |
1. DPD (Dead Peer Detection)
IKE Phase 2 (IPsec SA) 에서 Session lifetime 이 만료로 인해 session 이 끊긴다.
(* 1. lifetime 만료되기 전에 DPD 보내서 응답 올 경우 재협상하여 tunnel status 유지
그래서 보통 ike lifetime 은 8 hours
ipsec lifetime 은 1 hours 로 설정하여 phase 2 만료되기 전에 DPD 로 phase 1 (ike) 체크하여 최종 재협상 *)
이러한 현상을 방지하기 위해 VPN내 연결을 끊김이 업게끔 하기위해 VPN구간내의 패킷 , 즉 Interesting packet 을 계속 발생시켜줘
야한다.
( 보통, 이러한 설정은 장비마다 있긴하지만 없을 경우 , 1. DPD 2. Tunnel monitor ) 등 설정을 통해 keepalive 패킷을 보내서 활성화.
시키도록 한다.
**** DPD 정의 ****
Dead Peer Detection(DPD)은 RFC 3706에 문서화된 기능을 말하며, 이는 Dead Internet Key Exchange(IKE/Phase1) 피어를 감지하는 방법입니다. 터널 모니터링은 Palo Alto Networks 독점 기능으로 터널에서 구성된 대상으로 PING을 전송하여 문제의 IPSec 터널을 통해 트래픽이 성공적으로 전달되고 있는지 확인합니다. 터널 모니터링은 "모니터 프로필"과 함께 사용하여 터널 인터페이스를 중단하여 트래픽이 보조 경로를 통해 라우팅될 수 있도록 라우팅을 업데이트할 수 있습니다. 터널 모니터링에는 DPD가 필요하지 않습니다. Dead Peer Detection은 터널의 양쪽에서 활성화되거나 비활성화되어야 합니다. 한쪽은 DPD를 활성화하고 한쪽은 비활성화하면 VPN 안정성 문제가 발생할 수 있습니다.
2. [DPD 와 Keepalive 의 차이]
1. DPD 는 데이터를 보내고 있는 동안에는 체크를 하지않는다.
2. keepalive 는 데이터를 보내는 동안에도 체크를 주기적으로 한다
| NAT Traversal (0) | 2021.07.04 |
|---|
1. NAT Traversal 이란?
Ipsec vpn 연결 및 맺기위한 과정의 IKE Phase 1 , 2 를 맺는 과정 중
[IKE Main mode - Phase 1] 에서
- 1,2 단계에서 NAT enable 여부를 체크한다.
- 3,4 단계에서 NAT 가 됬는지 안됬는지 체크한다.
- 5,6 단계에서 UDP 4500 이라는 정보를 추가로 붙여서 (NAT , PAT 가 됬건 상관업이 서로간의 문제업이 통신할수 있게끔 만
들어지게 된것 )
| DPD (Dead Peer Detection) (0) | 2021.07.04 |
|---|
핑의 첫번째 패킷이 항상 실패하는 경우 | 첫번째 핑이 실패하는 이유
우리가 장비 설정 후 ping 통신을 통해 상대방의 장비와 연결 상태를 확인 하다보면
첫번째 ping 이 실패하는 경우가 있다. 그 이유에 대해서 설명하겠습니다.
Router#ping 10.0.0.100
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.0.100, timeout is 2 seconds:
.!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 9/13/24 ms
PC>ping 172.16.0.100
Pinging 172.16.0.100 with 32 bytes of data:
Request timed out.
Reply from 172.16.0.100: bytes=32 time=21ms TTL=125
Reply from 172.16.0.100: bytes=32 time=13ms TTL=125
Reply from 172.16.0.100: bytes=32 time=13ms TTL=125
Ping statistics for 172.16.0.100:
Packets: Sent = 4, Received = 3, Lost = 1 (25% loss),
Approximate round trip times in milli-seconds:
Minimum = 13ms, Maximum = 21ms, Average = 15ms
1. ARP 캐시가 비어 있는 경우
- 송신 시스템의 ARP 캐시에 목적지 시스템을 나타내는 엔트리가 없다면, 목적지 장비의 하드웨어 주소를 파악하는데 걸리는 시간이 핑 클라이언트에 정의된 시간 제한을 초과 할 수 있다. 또 ICMP Echo Request 메시지의 크기가 로컬 시스템의 MTU보다 크면, 핑은 첫번째 조각을 자신의 Call-Back 큐로부터 삭제하여 첫번째 데이터그램의 두번째 이후 조각만을 전송할 수도 있다. 이런 경우 IP 패킷이 완전하지 않으므로 목적지 시스템은 그 패킷을 무시한다.
2. 라우팅 캐시가 피어 있는 경우
- 오늘날 인터넷은 수백만 개의 네트웍크로 구성되어 있으며, 라우터 대부분이 다른 모든 라우터를 추적할 수 없다. 실제로 대부분의 라우터는 항상 자신의 캐시에 몇 개의 라우팅 경로만을 지정한다. 이런 경우에 패킷이 최근에 전송된 적이 없는 네트웍크로 보내진다면, 라우터가 패킷을 따라야할 올바른 네트웍크 경로를 정하는 데에 다소 시간이 걸릴 수 있다. 따라서, ICMP Echo Request질의 메시지가 성공적으로 응답되기 이전에 핑 클라이언트의 제한 시간이 초과될 수도 있다. 이런 경우, 핑은 처음 몇 개의 메시지를 분실된 것으로 표시할 수도 있다.
3. DNS네임 캐시가 비어 있을 경우
- 핑의 인자로 호스트명을 사용한다면 DNS 탐색 작업으로 인하여 일부 메시지가 지연될 수 있으며, 처리 도중 큐에서 사라지거나 "시간 초과"로 잘못 보고될 수도 있다. 따라서 네트웍크를 조사할 때, 항상 IP주소를 사용하여 이름 변환작업이 시스템 검사에 방해되지 않도록 해야 한다.
# ICMP 트래픽을 차단하는 방화벽
- 웹 서버에 핑을 한다고 하자, Http를 사용하여 웹 서버에 접속할 수는 있어도 핑을 사용하면 아무런 응답도 얻지 못할 수 있다. 이런 경우 ICMP Echo Request메시지가 원격 네트웍크로 보내지지만 원격 네트웍크의 방화벽이 모든 ICMP 메시지를 차단하는 것일 수 있다. 이런 경우 ICMP 메시지는 방화벽에 의해 소멸되며 아무런 ICMP메시지도 응답되지 않는다.
원격 방화벽에서 Destination Unreachable에러 메시지를 전송한다면 문제의 원인을 쉽게 파악할 수 있다. 그러나 이런 메시지를 전송하는 것이 보안에 위배된다고 생각하여 방화벽에서 메시지를 전송하지 않도록 설정하는 경우가 많다. 이런 경우 송신 시스템은 아무런 메시지도 수신하지 못하게 된다.
# 설정이 잘못된 라우팅 테이블
- 송신 시스템의 데이터그램이 원격 목적지에 전송되고, 이에 응답하는 데이터그램이 다시 송신 시스템으로 전송된다. 하지만 잘못된 경로를 통해 송신 시스템의 네트웍크로 보내지는 경우도 있다. 이런 문제는 송신 시스템의 네트웍크가 잘못된 경로를 가리키는 경로로 통지되는 경우에 발생한다.
이런 문제는 새로운 또는 최근에 변경된 네트웍크에서 흔하게 찾아 볼 수 있다. 새로운 네트웍크에 이르는 경로를 정의하는 것을 잊어 버릴 수도 있다. 데이터그램이 돌아 올 때, 반드시 전송되었던 경로와 같은 경로로 되돌아 오는 것은 아니다.
# 많은 양의 Redirect 에러 메시지
- 일부 네트웍크는 많은 양의 ICMP Redirect 에러 메시지를 생성하는 것으로 알려져 있다.
일반적으로 이것은 호스트와 라우터의 서브넷 마스크가 잘못 설정된 경우 또는 호스트를 설정하기 위해 Router Discovery에 심하게 의존하는 경우 발생한다
1. Router Discovery
- 네트웍 장비는 Router Solicitation 질의 메시지에 응답한 라우터 가운데 가장 가중치가 높은 오직 하나의 라우터를 기본 라우터로 사용한다. 이런 모델에서 호스트는 특정 목적지 시스템을 위해 더 적합한 라우터를 통보 받지 않는 한 로컬이 아닌 모든 데이터그램을 전송하는 데 기본 라우터를 사용한다. 그러므로 네트웍크에 여러 개의 라우터가 있다면, 호스트가 여러 라우터와 그 라우터에서 지원하는 경로를 알게됨에 따라 여러개의 ICMP Redirect에러 메시지를 수신하게 된다.
만약 잘못된 라우터에 가장 높은 가중치 값을 부여했다면, 다른 라우터에 더 높은 우선 순위를 부여함으로써 네트웍크의 ICMP Redirect에러 메시지의 수를 줄일 수 있다. 또 다른 방법은 라우터를 집중시켜 하나의 라우터에서만 로컬 세그먼트를 취급하도록 하는 것이다. 이런 경우 모든 트래픽은 남겨진 한 라우터만을 통과하며, 로컬 세그먼트의 모든 ICMP Redirect 트래픽은 없어진다.
2. 잘못 설정된 서브네 마스크
- 네트워크에 잘못 설정된 서브네 마스크를 가진 호스트가 존재하면, ICMP Redirect에러 메시지가 대량으로 생성된다. 이런 로컬 네트웍크의 다른 시스템과 연결을 시도하는 경우 호스트는 목적지 시스템이 다른 네트웍크에 존재하는 것으로 오인하여 데이터그램을 로컬 라우터에 보내게 돈다. 그런 경우, 라우터는 송신 시스템에게 목적지 시스템이 로컬에 존재한다는 것을 Redirect에러 메지지를 통해 알린다.
이 문제를 해결하는 최선의 방법은 네트웍크 장비에 올바른 서브넷 마스크를 부여하여 장비들이 라우터를 거치지 않고 직접 통신 할 수 있게 하는 것이다.
[첫번째 핑이 실패하는 경우, Request timed out.]
| 와일드카드 마스크 예제 (Wildcard Mask) (0) | 2022.05.15 |
|---|---|
| FTP - Active & Passive 모드 차이 (0) | 2022.05.14 |
| [네트워크 기초 1] IPv4 Header 헤더 구조 (0) | 2021.08.09 |
- 자신의 앱 또는 웹사이트에서 사용자 인증을 위해 다른 앱 또는 웹사이트의 사용자 인증 방식으로 허락(인가) 받는 프로토콜
- 해당 앱의 ID/PW 로 직접 로그인하는 방식과는 범위의 제약이 존재
- 토큰 인증 방식 사용
ex) 회사를 예로 들면,
-> 회사의 직원이 회사 내부에서 출입이 가능한 범위가 방문증을 받은 사람의 출입 가능 범위보다 더 클 수 밖에 없다.
ex2) 실제 웹 사이트에서도
-> Facebook, Naver, Google 로 로그인한 사람들보단 직접 회원가입한 아이디로 로그인한 사람들에게 쿠폰, 할인 등 여러 헤택을 더욱 제공한다.

ex) Netflix 로그인을 예시로 들 경우
1) Netflix 접속
2) Facebook으로 로그인 클릭
3) Facebook 로그인 창 으로 이동
4) Facebook 로그인 성공
5) 접근 허용(또는 정보 제공) 여부 창 출력
6) 허용 클릭 시 로그인 성공 토큰(Token) 을 Facebook에서 발급
7) 발급받은 토큰을 이용하여 Netflix에서 활용
- Security Asserting Markup Language 의 약자(알 필요 없을 듯...)
- 네트워크를 통해 여러 컴퓨터에서 인증 및 권한 부여(SSO)를 하게 해주는 것.
- XML 을 사용하며, cross domain(크로스 도메인) 간 SSO 구현이 가능하다.
*** 좀 더 깊게 알고 싶으시면, 하단 사이트를 참고해주세요!
http://www.itworld.co.kr/news/108736
SAML에 대해 알아야 할 것
SAML(Security Assertion Markup Language)은 네트워크를 통해 여러 컴퓨터에서 보안 자격 증명을 공유할 수 있도록 하는 공개 표준이다. 한 대의 컴퓨터가 하나 이상의 다른 컴퓨터를 대신해 몇 가지 보안
www.itworld.co.kr
- 위 그림과 같이, 로그인 / 인증 을 위한 SSO 모듈이 중간에 존재한다. (이를 Identify Provider라고 한다.)
- 웹 사이트는 Service Provider 라고 한다.

- 한 번도 로그인하지 않은 경우
1) 사용자가 SP를 사용하기 위해 접근한다.
2) SP에 해당 사용자의 세션(정보) 이 저장되어있는지 체크한다.
3) SP에 세션이 저장되어 있지 않아, IdP로 Redirect 한다. (SSO 인증 모듈로 이동)
4) IdP에도 세션이 저장되어 있지 않아, 로그인(또는 인증) 페이지를 통해 사용자가 로그인하도록 한다.
5) 로그인에 성공하면, IdP에 해당 사용자의 세션(정보)를 저장한 후 SP로 Redirect 한다. (페이지 이동)
6) SP 에도 세션을 저장한 후(로그인 성공 전달) 사용자가 SP를 사용할 수 있도록 한다
- 기존에 한 번 이상 로그인한 경우
1) 사용자가 SP를 사용하기 위해 접근한다.
2) SP에 해당 사용자의 세션(정보) 이 저장되어있는지 체크한다.
3) SP에 세션이 저장되어 있지 않아, IdP로 Redirect 한다. (SSO 인증 모듈로 이동)
** 3 - 1) SP에 세션이 저장되어 있는 경우 세션에 맞게 사용자가 SP를 사용할 수 있도록 한다.
4) IdP에 세션이 저장되어 있어, 해당 세션을 가지고 SP로 Redirect 한다. (페이지 이동)
5) SP에 IdP에서 가져온 세션을 저장한 후(로그인 성공 전달) 사용자가 SP를 사용할 수 있도록 한다.
안녕하세요.
최근들어 모든 웹이나 앱을 보시면
첫 로그인 시 "Facebook, Naver, Google 로 로그인하기" 라는 것을 많이 보셨을 것입니다.
예전에는 하나의 웹 또는 앱 을 이용하려면
각각 회원가입하고 그 아이디와 비밀번호를 입력해서 로그인을 했어야 했는데
어느새부터 구글 또는 네이버 계정만 있으면 대부분 로그인이 가능합니다. (별도 회원가입이 필요한 경우도 있지만..)
어떻게 이런 것이 가능한지? 이 것을 뭐라고 말하는지 에 대해 짚고 넘어가는 포스팅입니다.
[ SSO ] 란?
- Single Sign-On 의 약자로써, 한 번의 로그인으로 다른 사이트(서비스)들을 인증할 수 있는 것.
- 다른 사이트(또는 앱) 에서 로그인 및 인증 부분만 따로 사용하는 것. (API, 모듈 등)
- 통합 인증, 단일 계정 로그인, 단일 인증 이라고 한다.
ex)
네이버 메일, 네이버 블로그, 네이버 클라우드 세 개의 서비스가 있다고 하자.
어떤 사람이 네이버 메일을 사용하기 위해 로그인을 한 이후 블로그, 클라우드를 사용하고자 한다면
-> 블로그, 클라우드 이용 시 별도 로그인 없이 이용이 가능하다.
